2. 現代商用硬體
肇因於專屬硬體的式微,了解商用硬體變得非常重要。 如今,水平發展比垂直發展更常見,這意味著使用許多小型且相互連接的商用電腦成本效益更高,而非少數幾個巨大且極快 (也非常昂貴) 的系統。 這是因為快速且便宜的網路硬體已經普及,雖然大型專用系統仍在某些情況下佔有一席之地,且仍具有商機,但整體市場已被商用硬體市場所主導。 Red Hat 在 2007 年預測,未來大多數資料中心的「標準建構元件」(building block) 將是一台具有最多 4 個插槽 (socket) 的電腦, 每個插槽具備一顆 4 核的處理器,這些處理器 (例如 Intel 公司生產的 CPU) 將使用超執行緒 (hyper-threading,簡稱 HT) 技術2。 這意味著標準資料中心系統將具有最多 64 個虛擬處理器譯註1。 當然,也可支援更大的機器,但 2007 年原文撰寫之際,4 個插槽、4 核的處理器會是最適合的配置,且大多數最佳化都針對這種硬體配置進行。
商用元件所構建的電腦在結構上存在著重大的差異,儘管如此,我們將專注於最重要的差異,以涵蓋超過 90% 的這類硬體。 需要注意的是,這些技術細節日新月異,因此建議讀者留意原文撰寫日期。
過去的數年中,個人電腦和小型伺服器已標準化為一個晶片組 (chipset),並由二個主要組件組成:北橋 (Northbridge) 和南橋 (Southbridge)。 圖 2.1 展現這種結構。
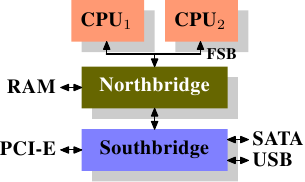
所有 CPU (前例中有二顆,但可有更多) 都透過一條共用的匯流排,即前端匯流排 (Front Side Bus,簡稱 FSB),連接到北橋。 北橋包含記憶體控制器 (memory controller),其實作決定在電腦中使用的 RAM 晶片類型。 不同類型的 RAM,諸如 DRAM、Rambus 和 SDRAM,需要不同的記憶體控制器。 為與其他系統裝置連接,北橋必須與南橋進行通訊,其中南橋通常稱為 I/O 橋接,藉由各種不同的匯流排與各個裝置進行通訊。 現今南橋支援 PCI、PCI Express、SATA 和 USB 等最重要的匯流排,及 PATA、IEEE 1394、序列埠 (serial port) 和平行埠 (parallel port)。 在較老的系統中,北橋附帶有 AGP 槽,這是由於南北橋之間的連接速度不夠快的性能因素,然而,現代的 PCI-E 槽都連接到南橋上。
這種系統結構具有一些值得注意的結果:
- 從一顆 CPU 到另一顆 CPU 的所有資料通訊,都必須經由與北橋通訊的同一條匯流排。
- 所有與 RAM 的通訊都必須經由北橋進行。
- RAM 只有單個埠口3。
- 一顆 CPU 與一個依附於南橋的裝置之間的通訊會經由北橋。
幾個瓶頸立刻在這種設計中顯現出來,其一涉及裝置對 RAM 的存取。 在早期的個人電腦中,所有裝置 (無論在南橋還是北橋上) 與 RAM 的通訊都必須經過 CPU,這對整體系統效能產生負面影響。 為解決這個問題,一些裝置開始支援直接記憶體存取 (Direct Memory Access,簡稱 DMA)。DMA 允許裝置藉由北橋的幫助, 在不需要 CPU 介入 (及相應的效能成本) 的情況下,直接儲存和接收 RAM 中的資料。 現今所有連接到匯流排上的高效能裝置都可使用 DMA,儘管這大幅減輕 CPU 的工作負擔,但這也引起北橋頻寬的競爭, 因為 DMA 請求與 CPU 對 RAM 存取的競爭。因此,這個問題必須納入考慮。
第二個瓶頸涉及從北橋到 RAM 的匯流排,其具體細節取決於所使用的記憶體類型。 在較舊的系統中,只有一條匯流排連接所有的 RAM 晶片,因此平行存取是不可能的。 近期的記憶體類型需要二條獨立的匯流排 (或稱通道〔channel〕,例如 DDR2 所稱之,見圖 2.8),以增加可用的頻寬。 北橋交錯使用這些通道進行記憶體存取,更現代的記憶體技術 (如 FB-DRAM) 則引入更多通道。
由於頻寬有限,以最小化延遲的方式安排記憶體存取對效能至關重要。 如同我們將在後面所見,處理器比記憶體快得多,且必須等待存取記憶體,即便使用 CPU 快取仍是。 如果多個超執行緒 (HT) 或多個處理器核心同時存取記憶體,那麼記憶體存取的等待時間可能會更長,對於 DMA 操作也是如此。
然而,除了並行性 (concurrency) 之外,存取記憶體還存在許多問題。存取模式 (access pattern) 本身也會對記憶體子系統的效能產生顯著影響, 尤其是在具有多個記憶體通道的情況下,在第 2.2 節中,我們將深究 RAM 存取模式的更多細節。
在一些高價的系統中,北橋不含記憶體控制器,相反地,北橋可連接到多個外部記憶體控制器 (下例中,共有 4 個控制器)。
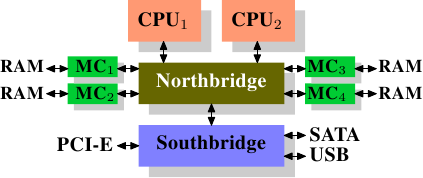
該架構的好處是擁有多個記憶體匯流排,從而增加整體可用頻寬,此設計還支援多個記憶體模組。 並行記憶體存取模式藉由同時存取不同的記憶庫 (memory bank) 來降低延遲,尤其是在多個處理器直接連接到北橋的情況下 (如圖 2.2 所示)。 對於這種設計,主要的限制在於北橋的內部頻寬,對於這種 (來自 Intel 公司) 的架構而言,該頻寬非常大4。
使用多個外部記憶體控制器並非提高記憶體頻寬的唯一方法,另一種越來越受歡迎的方式是將記憶體控制器整合到 CPU 中,並將記憶體附加到每顆 CPU 上。 該架構在基於 AMD 公司的 Opteron 處理器的 SMP 系統中很流行,如圖 2.3 所示。 Intel 也從 Nehalem 微處理器架構開始,支援通用系統介面 (Common System Interface,簡稱 CSI),基本上也是相同的方法:一個整合式記憶體控制器,讓每個處理器都擁有區域記憶體 (local memory)。
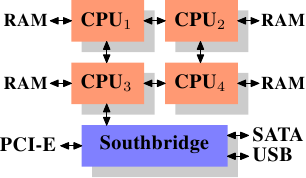
採用這種架構,每個處理器都有一個可用的記憶庫,例如在一台 4 核 CPU 的機器上,無需複雜的北橋即可將記憶體頻寬提高 4 倍。 整合到 CPU 的記憶體控制器也具有一些額外的優點,但在此我們不會深究這些技術。
然而,這種架構也有一些缺點。 首先,由於系統上的所有記憶體都需要供所有處理器存取,記憶體不再是均勻的 (uniform), 這種系統稱為非均勻記憶體架構 (Non-Uniform Memory Architecture,簡稱 NUMA)。 當存取附屬於其他處理器的記憶體時,必須藉由處理器之間的交互連線 (interconnect), 從 CPU1 存取 CPU2 的記憶體就需要一條交互連線,而從 CPU1 存取 CPU4 的記憶體則需要二條交互連線。
每次這樣的通訊都會帶來一些成本,我們稱之為「NUMA 因子」(NUMA factor),用於描述存取遠端 (remote) 記憶體所需的額外時間。 在圖 2.3 所示的範例架構中,每顆 CPU 都有二個層級:與其鄰近的 CPU 和相隔二條交互連線的 CPU,在較複雜的系統中,層級的數量會顯著增加。 某些架構 (如 IBM 公司的 x445 和 SGI 公司的 Altix 系列) 具有不止一種連線類型。CPU 被組織成節點,存取同一節點內的記憶體具有一致或較低的 NUMA 因子。 然而,節點之間的連線成本很高,NUMA 因子也很高。
現在商用的 NUMA 機器已問世,並可能在未來扮演更重要的角色。預計到 2008 年末,每個 SMP 機器都將使用 NUMA譯註2。 當一個程式在 NUMA 機器上運行時,了解 NUMA 相關的成本非常重要。我們將在第五節中討論更多有關機器架構以及 Linux 核心 (kernel譯註3) 為這些程式提供的技術。
除了本節描述的技術細節外,尚有許多其他影響 RAM 效能的因素無法由軟體控制,這也是為何它們不在本節中涵蓋。 對於對 RAM 技術希望有更全面理解的讀者來說,這些因素有助於在購買電腦時做出更好的選擇。
接下來的二節將在邏輯閘 (gate) 層級討論硬體細節,並介紹記憶體控制器和 DRAM 晶片之間的通訊協定 (protocol)。 對程式開發者而言,這些資訊可能會帶來更深入的理解,因為它們解釋 RAM 存取的運作原理。 然而,這些都是選讀的知識,對於那些更關注與日常生活直接相關的主題的讀者來說,可直接跳到第 2.2.5 節。
2. 超執行緒 (HT) 使得一顆處理器核僅需少量的額外硬體,就能被用來同時處理 2 個或多個任務。 ↩
3. 我們不會在本文討論多埠 RAM,因為這種 RAM 在商用硬體中並不常見,至少不在尋常程式開發者可存取的範圍內。多埠 RAM 主要用於依賴極限速度的專用硬體,例如網路路由器等設備中。 ↩
4. 完整起見,這裡需要提到一下,這類記憶體控制器佈局可以被用於其它用途,像是「記憶體 RAID」,它很適合與熱插拔(hotplug)記憶體組合使用。 ↩
譯註1. 這句的原文是 "the standard system in the data center will have up to 64 virtual processors",注意到本文發表的時間點在 2007 年,本句是 Red Hat 公司之前的推論,64 個虛擬處理器核意味著 4 個插槽、HT (即 2 個硬體執行緒),和每個 CPU 要有 8 核,不過這樣的硬體配置要到 2014 年的 POWER8 才出現,後者的每個 CPU 可有 6 或 12 核。原文作者 Ulrich Drepper 撰寫文章時,任職於 Red Hat 公司,這也是為何文中提及 Red Hat,後來他一度在高盛服務,並於 2017 年回歸。 ↩
譯註2. 這陳述不成立,如今 SMP 架構廣為個人電腦、移動裝置,甚至是嵌入式系統所採納,但 NUMA 仍只在部分 SMP 系統存在。 ↩
譯註3. 為了區分 (OS) kernel 和 (processor) core,本文將前者稱為「核心」(例如 Linux 核心),而將後者稱為「核」(例如處理器核)。 ↩