6.2.2. 最佳化一階指令快取存取
準備有效使用 L1i 的程式碼需要與有效使用 L1d 類似的技術。不過,問題是,程式開發者通常不會直接影響 L1i 的使用方式,除非他以組合語言來撰寫程式。若是使用編譯器,程式開發者能夠透過引導編譯器建立更好的程式佈局,來間接地決定 L1i 的使用。
程式有跳躍(jump)之間為線性的優點。在這些期間,處理器能夠有效地預取記憶體。跳躍打破這個美好的想像,因為
- 跳躍目標(target)可能不是靜態決定的;
- 而且即使它是靜態的,若是它錯失所有快取,記憶體獲取可能會花上很長一段時間。
這些問題造成執行中的停頓,可能嚴重地影響效能。這即是為何現今的處理器在分支預測(branch prediction,BP)上費盡心思的原因。高度特製化的 BP 單元試著盡可能遠在跳躍之前確定跳躍的目標,使得處理器能夠開始將新的位置的指令載入到快取中。它們使用靜態與動態規則、而且越來越擅於判定執行中的模式。
對指令快取而言,盡早將資料拿到快取甚至是更為重要的。如同在 3.1 節提過的,指令必須在它們被執行之前解碼,而且 –– 為了加速(在 x86 與 x86-64 上很重要)–– 指令實際上是以被解碼的形式、而非從記憶體讀取的位元組/字組的形式被快取的。
為了達到最好的 L1i 使用,程式開發者至少應該留意下述的程式碼產生的面向:
- 盡可能地減少程式碼量(code footprint)。這必須與像是迴圈展開(loop unrolling)與行內展開(inlining)等最佳化取得平衡。
- 程式執行應該是沒有氣泡(bubble)的線性的。31
- 合理的情況下,對齊程式碼。
我們現在要看一些根據這些面向、可用於協助最佳化程式的編譯器技術。
編譯器有啟動不同最佳化層級的選項,特定的最佳化也能夠個別地啟用。在高最佳化層級(gcc 的 -O2 與 -O3)啟用的許多最佳化處理迴圈最佳化與函式行內展開。一般來說,這些是不錯的最佳化。如果以這些方式最佳化的程式碼佔了程式總執行時間的很重要的一部分,便能夠提升整體的效能。尤其是,函式的行內展開允許編譯器一次最佳化更大的程式碼塊(chunk),從而能夠產生更好地利用處理器的管線架構的機器碼。當程式較大的一部分能被視為一個單一單元時,程式碼與資料的處理(透過死碼消除〔dead code elimination〕或值域傳播〔value range propagation〕、等等)的效果更好。
較大的程式容量意味著 L1i(以及 L2 與更高階層)快取上的壓力更大。這可能導致較差的效能。較小的程式可能比較快。幸運的是,gcc 有一個針對於此的最佳化選項。如果使用 -Os,編譯器將會為程式容量最佳化。已知會增加程式容量的最佳化會被關掉。使用這個選項經常產生驚人的結果。尤其在編譯器無法真的獲益於迴圈展開與行內展開的情況下,這個選項就是首選。
行內展開也能被個別處理。編譯器擁有引導行內展開的啟發法(heuristic)與限制;這些限制能夠由程式開發者控制。-finlinelimit 選項指定對行內展開而言,必須被視為過大的函式有多大。若是一個函式在多處被呼叫,在所有函式中行內展開它便會導致程式容量的劇增。但還有更多細節。假設一個函式 inlcand 在二個函式 f1 與 f2 中被呼叫。函式 f1 與 f2 本身是先後被呼叫的。
|
|
表 6.3 顯示在二個函式中沒有行內展開與行內展開的情況下,產生的程式碼看起來會怎麼樣。若是函式 inlcand 在 f1 與 f2 中被行內展開,產生的程式碼的容量為 size f1 + size f2 + size inlcand。如果沒有進行行內展開的話,總容量減少 size inlcand。這即是在 f1 與 f2 相互在不久後呼叫的話,L1i 與 L2 快取額外所需的量。再加上:若是 inlcand 沒被行內展開,程式碼可能仍在 L1i 中,而它就不必被再次解碼。再加上:分支預測單元或許能更好地預測跳躍,因為它已經看過這段程式。如果對程式而言,被行內展開的函式容量上限的編譯器預設值並不是最好的,它應該要被降低。
不過,有些行內展開總是合理的情況。假如一個函式只會被呼叫一次,它也應該被行內展開。這給編譯器執行更多最佳化的機會(像是值域傳播,其會顯著地改進程式碼)。行內展開也許會受選擇限制所阻礙。對於像這樣的情況,gcc 有個選項來明確指定一個函式總是要被行內展開。加上 always_inline 函式屬性會命令編譯器執行恰如這個名稱所指示的操作。
在相同的情境下,若是即便一個函式足夠小也不該被行內展開,能夠使用 noinline 函式屬性。假如它們經常從多處被呼叫,即使對於小函式,使用這個屬性也是合理的。若是 L1i 內容能被重複使用、並且整體的程式碼量減少,這往往彌補額外函式呼叫的附加成本。如今分支預測單元是非常可靠的。若是行內展開能夠促成更進一步的最佳化,情況就不同。這是必須視情況來決定的。
如果行內展開的程式碼總是會被用到的話,always_inline 屬性表現得很好。但假如不是這樣呢?如果偶爾才會呼叫被行內展開的函式會怎麼樣:
void fct(void) {
... code block A ...
if (condition)
inlfct()
... code block C ...
為這種程式序列產生的程式碼一般來說與原始碼的結構相符。這表示首先會是程式區塊 A、接著是一個條件式跳躍 –– 假如條件式被求值為否(false),就往前跳躍。接下來是為行內展開的 inlfct 產生的程式碼,最後是程式區塊 C。這看起來全都很合理,但它有個問題。
若是 condition 經常為否,執行就不是線性的。中間有一大塊沒用到的程式碼,不僅因為預取污染 L1i,它也會造成分支預測的問題。若是分支預測錯,條件表示式可能非常沒有效率。
這是個普遍的問題,而且並不專屬於函式的行內展開。無論在何時用到條件執行、而且它是不對稱的(即,表示式比起某一種結果還要更常產生另一種結果),就有不正確的靜態分支預測、從而有管線中的氣泡的可能性。這能夠藉由告知編譯器,以將較不常執行的程式碼移出主要的程式路徑來避免。在這種情況下,為一個 if 敘述產生的條件分支將會跳躍到一個跳脫順序的地方,如下圖所示。
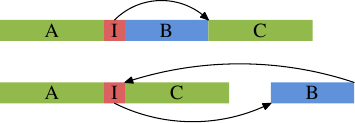
上半部表示單純的程式佈局。假如區域 B –– 即,由上面被行內展開的函式 inlfct 所產生的 –– 因為條件 I 跳過它而經常不被執行,處理器的預取會拉進包含鮮少用到的區塊 B 的快取行。這能夠藉由區塊的重新排列來改變,其結果能夠在圖的下半部看到。經常執行的程式碼在記憶體中是線性的,而鮮少執行的程式碼被移到不傷及預取與 L1i 效率的某處。
gcc 提供二個實現這點的方法。首先,編譯器能夠在重新編譯程式碼的期間將效能分析(profiling)的輸出納入考量,並根據效能分析擺放程式區塊。我們將會在第七節看到這是如何運作的。第二個方法則是藉由明確的分支預測。gcc 認得 __builtin_expect:
long __builtin_expect(long EXP, long C);
這個結構告訴編譯器,表示式 EXP 的值非常有可能會是 C。回傳值為 EXP。__builtin_expect 必須被用在條件表示式中。在幾乎所有的情況中,它會被用在布林表示式的情境中,在這種情況下定義二個輔助巨集(macro)要更方便一些:
#define unlikely(expr) __builtin_expect(!!(expr), 0)
#define likely(expr) __builtin_expect(!!(expr), 1)
然後可以像這樣用這些巨集
if (likely(a > 1))
若是程式開發者使用這些巨集、然後使用 -freorder-blocks 最佳化選項,gcc 會如上圖那樣重新排列區塊。這個選項會隨著 -O2 啟用,但對於 -Os 會被停用。有另一個重新排列區塊的 gcc 選項(-freorder-blocks-and-partition),但它的用途有限,因為它不適用於例外處理。
還有另一個小迴圈的大優點,至少在某些處理器上。Intel Core 2 前端有一個特殊的功能,稱作迴圈指令流檢測器(Loop Stream Detector,LSD)。若是一個迴圈擁有不多於 18 道指令(沒有一個是對子程式〔routine〕的呼叫)、僅要求至多 4 次 16 位元組的解碼器擷取、擁有至多 4 條分支指令、並且被執行超過 64 次,那麼這個迴圈有時會被鎖在指令佇列中,因而在迴圈被再次用到的時候能夠更為快速地使用。舉例來說,這適用於會通過一個外部迴圈進入很多次的很小的內部迴圈。即使沒有這種特化的硬體,小巧的迴圈也有優點。
就 L1i 而言,行內展開並非最佳化的唯一面向。另一個面向是對齊,就如資料一般。但有些明顯的差異:程式大部分是線性的一團,其無法任意地擺在定址空間中,而且它無法直接受程式開發者影響,因為是編譯器產生這些程式的。不過,有些程式開發者能夠控制的面向。
對齊每條單一指令沒有任何意義。目標是令指令流為連續的。所以對齊僅在戰略要地上才有意義。為了決定要在何處加上對齊,理解能有什麼好處是必要的。有條在一個快取行開頭的指令32代表快取行的預取是最大化的。對指令而言,這也代表著解碼器是更有效的。很容易看出,若是執行一條在快取行結尾的指令,處理器就必須準備讀取一個新的快取行、並對指令解碼。有些事情可能會出錯(像是快取行錯失),代表平均而言,一條在快取行結尾的指令執行起來並不跟在開頭的指令一樣有效。
如果控制權剛轉移到在快取行結尾的指令(因此預取無效),則情況最為嚴重。將以上推論結合後,我們得出對齊程式碼最有用的地方:
- 在函式的開頭;
- 在僅會通過跳躍到達的基礎區塊的開頭;
- 對某些擴充而言,在迴圈的開頭。
在前二種情況下,對齊的成本很小。在一個新的位置繼續執行,假如決定讓它在快取行的開頭,我們便最佳化預取與解碼。33編譯器藉由無操作(no-op)指令的插入,填滿因對齊程式產生的間隔,而實現這種對齊。這種「死碼(dead code)」佔用一些空間,但通常不傷及效能。
第三種情況略有不同:對齊每個迴圈的開頭可能會造成效能問題。問題在於,一個迴圈的開頭往往是連續地接在其它的程式碼之後。若是情況不是非常湊巧,便會有個在前一道指令與被對齊的迴圈開頭之間的間隔。不像前二種情況,這個間隔無法完全不造成影響。在前一道指令執行之後,必須執行迴圈中的第一道指令。這表示,在前一道指令之後,要不是非得有若干條無操作指令以填補間隔、要不就是非得有個到迴圈開頭的無條件跳躍。二種可能性都不是免費的。特別是迴圈本身並不常被執行的話,無操作指令或是跳躍的開銷可能會比對齊迴圈所省下的還多。
有三種程式開發者能夠影響程式對齊的方法。顯然地,若是程式是以組合語言撰寫,其中的函式與所有的指令都能夠被明確地對齊。組合語言為所有架構提供 .align 假指令(pseudo-op)以做到這點。對高階語言而言,必須將對齊需求告知編譯器。不像資料型別與變數那樣,這在原始碼中是不可能的。而是要使用一個編譯器選項:
-falign-functions=N
這個選項命令編譯器將所有函式對齊到下一個大於 N 的二的冪的邊界。這表示會產生一個至多 N 位元組的間隔。對小函式而言,使用一個很大的 N 值是個浪費。對只有難得才會執行的程式也相同。在可能同時包含常用與沒那麼常用的介面的函式庫中,後者可能經常發生。選項值的明智選擇可以藉由避免對齊來讓工作加速或是節省記憶體。能夠藉由使用 1 作為 N 的值、或是使用 -fno-align-functions 選項來關掉所有的對齊。
有關前述的第二種情況的對齊 –– 無法循序達到的基礎區塊的開頭 –– 能夠使用一個不同的選項來控制:
-falign-jumps=N
所有其它的細節都相同,關於浪費記憶體的警告也同樣適用。
第三種情況也有它自己的選項:
-falign-loops=N
再一次,同樣的細節與警告都適用。除了在這裡,如同先前解釋過的,對齊會造成執行期的成本,因為在對齊的位址會被循序地抵達的情況下,要不是必須執行無操作指令就是必須執行跳躍指令。
gcc 還知道一個用來控制對齊的選項,在這裡提起它僅是為了完整起見。-falign-labels 對齊了程式中的每個單一標籤(label)(基本上是每個基礎區塊的開頭)。除了一些例外狀況之外,這都會讓程式變慢,因而不該被使用。
31. 氣泡生動地描述在一個處理器的管線中執行的空洞,其會在執行必須等待資源的時候發生。關於更多細節,請讀者參閱處理器設計的文獻。 ↩
32. 對某些處理器而言,快取行並非指令的最小區塊(atomic block)。Intel Core 2 前端會將 16 位元組區塊發給解碼器。它們會被適當的對齊,因此沒有任何被發出的區塊能橫跨快取行邊界。對齊到快取行的開頭仍有優點,因為它最佳化預取的正面影響。 ↩
33. 對於指令解碼,處理器往往會使用比快取行還小的單元,在 x86 與 x86-64 的情況中為 16 位元組。 ↩