6.2.1. 最佳化一階資料快取存取
在 3.3 節,我們已經看過 L1d 快取的有效使用能夠提升效能。在這一節,我們會展示什麼樣的程式碼改變能夠協助改進這個效能。延續前一節,我們首先聚焦在循序存取記憶體的最佳化。如同在 3.3 節中看到的數字,處理器在記憶體被循序存取的時候會自動預取資料。
使用的範例程式碼為矩陣乘法。我們使用二個 double 元素的方陣(square matrices)。對於那些忘記數學的人,給定元素為 與 的矩陣 與 ,,乘積為
一個直觀的 C 實作看起來可能像這樣
for (i = 0; i < N; ++i)
for (j = 0; j < N; ++j)
for (k = 0; k < N; ++k)
res[i][j] += mul1[i][k] * mul2[k][j];
二個輸入矩陣為 mul1 與 mul2。假定結果矩陣 res 全被初始化為零。這是個既好又簡單的實作。但應該很明顯的是,我們有個正好是在圖 6.1 解釋過的問題。在 mul1 被循序存取的時候,內部的迴圈增加 mul2 的列號。這表示 mul1 是像圖 6.1 中左邊的矩陣那樣處理,而 mul2 是像右邊的矩陣那樣處理。這可能不太好。
有一個能夠輕易嘗試的可能補救方法。由於矩陣中的每個元素會被多次存取,是值得在使用第二個矩陣 mul2 之前將它重新排列(數學術語的話,「轉置〔transpose〕」)的。
在轉置之後(通常以上標「T」表示),我們現在循序地迭代二個矩陣。就 C 程式而言,現在看起來像這樣:
double tmp[N][N];
for (i = 0; i < N; ++i)
for (j = 0; j < N; ++j)
tmp[i][j] = mul2[j][i];
for (i = 0; i < N; ++i)
for (j = 0; j < N; ++j)
for (k = 0; k < N; ++k)
res[i][j] += mul1[i][k] * tmp[j][k];
我們建立一個容納被轉置的矩陣的暫時變數(temporary variable)。這需要動到額外的記憶體,但這個成本會被 –– 希望如此 –– 彌補回來,因為每行 1000 次非循序存取是更為昂貴的(至少在現代的硬體上)。是進行一些效能測試的時候。在有著 2666MHz 時脈的 Intel Core 2 上的結果為(以時鐘週期為單位):
| 原始 | 轉置 | |
|---|---|---|
| 週期數 | 16,765,297,870 | 3,922,373,010 |
| 相對值 | 100% | 23.4% |
雖然只是個簡單的矩陣轉置,但我們能達到 76.6% 的加速!複製操作的損失完全被彌補。1000 次非循序存取真的很傷。
下個問題是,我們是否能做得更好。無論如何,我們確實需要一個不需額外複製的替代方法。我們並不是總有餘裕能進行複製:矩陣可能太大、或者可用的記憶體太小。
替代實作的探尋應該從徹底地檢驗涉及到的數學與原始實作所執行的操作開始。簡單的數學知識讓我們能夠發現,只要每個加數(addend)正好出現一次,對結果矩陣的每個元素執行的加法順序是無關緊要的。28這個理解讓我們能夠尋找將執行在原始程式碼內部迴圈的加法重新排列的解法。
現在,讓我們來檢驗在原始程式碼執行中的實際問題。被存取的 mul2 元素的順序為:、、 ... 、、、、 ...。元素 與 位於同一個快取行中,但在內部迴圈完成一輪的時候,這個快取行早已被逐出。以這個例子而言,每一輪內部迴圈都需要 –– 對三個矩陣的每一個而言 –– 1000 個快取行(Core 2 處理器為 64 位元組)。這加起來遠比 L1d 可用的 32k 還多。
但若是我們在執行內部迴圈的期間,一起處理中間迴圈的二次迭代呢?在這個情況下,我們使用二個來自必定在 L1d 中的快取行的 double 值。我們將 L1d 錯失率減半。譯註這當然是個改進,但 –– 視快取行的容量而定 –– 也許仍不是我們能夠得到的最好結果。Core 2 處理器有個快取行容量為 64 位元組的 L1d。實際的容量能夠使用
sysconf (_SC_LEVEL1_DCACHE_LINESIZE)
在執行期查詢、或是使用命令列(command line)的 getconf 工具程式(utility),以讓程式能夠針對特定的快取行容量編譯。以 sizeof(double) 為 8 來說,這表示 –– 為了完全利用快取行 –– 我們應該展開內部迴圈 8 次。繼續這個想法,為了有效地使用 res 矩陣 –– 即,為了同時寫入 8 個結果 –– 我們也該展開外部迴圈 8 次。我們假設這裡的快取行容量為 64,但這個程式碼也能在 32 位元組快取行的系統上運作,因為快取行也會被 100% 利用。一般來說,最好在編譯期像這樣使用 getconf 工具程式來寫死(hardcode)快取行容量:
gcc -DCLS=$(getconf LEVEL1_DCACHE_LINESIZE) ...
若是二元檔是假定為一般化(generic)的話,應該使用最大的快取行容量。使用非常小的 L1d 表示並非所有資料都能塞進快取,但這種處理器無論如何都不適合高效能程式。我們寫出的程式碼看起來像這樣:
#define SM (CLS / sizeof (double))
for (i = 0; i < N; i += SM)
for (j = 0; j < N; j += SM)
for (k = 0; k < N; k += SM)
for (i2 = 0, rres = &res[i][j],
rmul1 = &mul1[i][k]; i2 < SM;
++i2, rres += N, rmul1 += N)
for (k2 = 0, rmul2 = &mul2[k][j];
k2 < SM; ++k2, rmul2 += N)
for (j2 = 0; j2 < SM; ++j2)
rres[j2] += rmul1[k2] * rmul2[j2];
這看起來超可怕的。在某種程度上它是如此,但只是因為它包含一些技巧。最顯而易見的改變是,我們現在有六層巢狀迴圈。外部迴圈以 SM(快取行容量除掉 sizeof(double))為間隔迭代。這將乘法切成多個能夠以更多快取局部性處理的較小的問題。內部迴圈迭代外部迴圈漏掉的索引。再一次,這裡有三層迴圈。這裡唯一巧妙的部分是 k2 與 j2 迴圈的順序不同。這是因為在實際運算中,僅有一個表示式取決於 k2、但有二個取決於 j2。
這裡其餘的複雜之處來自 gcc 在最佳化陣列索引的時候並不是非常聰明的結果。額外變數 rres、rmul1、與 rmul2 的引入,藉由將內部迴圈的常用表示式(expression)盡可能地拉出來,以最佳化程式碼。C 與 C++ 語言預設的別名規則(aliasing rule)並不能幫助編譯器做出這些決定(除非使用 restrict,所有指標存取都是別名的潛在來源)。這即是為何對於數值程式設計而言,Fortran 仍是一個偏好語言的原因:它令快速程式的撰寫更簡單。29
| 原始 | 轉置 | 子矩陣 | 向量化 | |
|---|---|---|---|---|
| 週期數 | 16,765,297,870 | 3,922,373,010 | 2,895,041,480 | 1,588,711,750 |
| 相對值 | 100% | 23.4% | 17.3% | 9.47% |
所有努力所帶來的成果能夠在表 6.2 看到。藉由避免複製,我們增加額外的 6.1% 效能。此外,我們不需要任何額外的記憶體。只要結果矩陣也能塞進記憶體,輸入矩陣可以是任意容量的。這是我們現在已經達成的一個通用解法的一個必要條件。
在表 6.2 中還有一欄沒有被解釋過。大多現代處理器現今包含針對向量化(vectorization)的特殊支援。經常被標為多媒體擴充,這些特殊指令能夠同時處理 2、4、8、或者更多值。這些經常是 SIMD(單指令多資料,Single Instruction, Multiple Data)操作,藉由其它操作的協助,以便以正確的形式獲取資料。由 Intel 處理器提供的 SSE2 指令能夠在一個操作中處理二個 double 值。指令參考手冊列出提供對這些 SSE2 指令存取的 intrinsic 函式。若是使用這些 intrinsic 函式,程式執行會變快 7.3%(相對於原始實作)。結果是,一支以原始程式碼 10% 的時間執行的程式。翻譯成人們認識的數字,我們從 318 MFLOPS 變為 3.35 GFLOPS。由於我們在這裡僅對記憶體的影響有興趣,程式的原始碼被擺到 A.1 節。
應該注意的是,在最後一版的程式碼中,我們仍然有一些 mul2 的快取問題;預取仍然無法運作。但這無法在不轉置矩陣的情況下解決。或許快取預取單元將會變得聰明地足以識別這些模式,那時就不需要額外的更動。不過,以一個 2.66 GHz 處理器上的單執行緒程式而言,3.19 GFLOPS 並不差。
我們在矩陣乘法的例子中最佳化的是被載入的快取行的使用。一個快取行的所有位元組總是會被用到。我們只是確保在快取行被逐出前會用到它們。這當然是個特例。
更常見的是,擁有塞滿一或多個快取行的資料結構,而程式在任何時間點都只會使用幾個成員。我們已經在圖 3.11 看過,大結構尺寸在只有一些成員被用到時的影響。
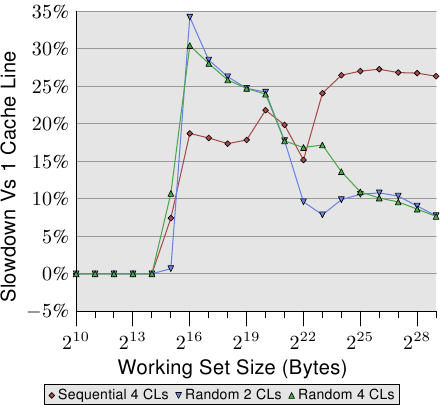
圖 6.2 顯示使用現在已熟知的程式執行另一組基準測試的結果。這次會加上同個串列元素的二個值。在一個案例中,二個元素都在同一個快取行內;在另一個案例中,一個元素位在串列元素的第一個快取行,而第二個位在最後一個快取行。這張圖顯示我們正遭受的效能衰減。
不出所料,在所有情況下,若是工作集塞得進 L1d 就不會有任何負面影響。一旦 L1d 不再充足,則是使用一個行程的二個快取行來償付損失,而非一個。紅線顯示串列被循序地排列時的數據。我們看到尋常的二步模式:當 L2 快取充足時的大約 17% 的損失、以及當必須用到主記憶體時的大約 27% 的損失。
在隨機記憶體存取的情況下,相對的數據看起來有點不同。對於塞得進 L2 的工作集而言的效能衰減介於 25% 到 35% 之間。再往後它下降到大約 10%。這不是因為損失變小,而是因為實際的記憶體存取不成比例地變得更昂貴。這份數據也顯示,在某些情況下,元素之間的距離是很重要的。Random 4 CLs 的曲線顯示較高的損失,因為用到第一個與第四個快取行。
要查看一個資料結構對比於快取行的佈局,一個簡單的方法是使用 pahole 程式(見 [4])。這個程式檢驗定義在二進位檔案中的資料結構。取一個包含這個定義的程式:
struct foo {
int a;
long fill[7];
int b;
};
當在一台 64 位元機器上編譯時,pahole 程式的輸出(在其它東西之中)包含顯示於圖 6.3 的輸出。這個輸出結果告知我們很多東西。首先,它顯示這個資料結構使用超過一個快取行。這個工具假設目前使用的處理器的快取行容量,但這個值能夠使用一個命令列參數來覆寫。尤其在結構容量幾乎沒有超過一個快取行、以及許多這種型別的物件會被分配的情況下,尋求一個壓縮這種結構的方式是合理的。或許幾個元素能有比較小的型別、又或者某些欄位實際上是能使用獨立位元來表示的旗標。
struct foo {
int a; /* 0 4 */
/* XXX 4 bytes hole, try to pack */
long int fill[7]; /* 8 56 */
/* --- cacheline 1 boundary (64 bytes) --- */
int b; /* 64 4 */
}; /* size: 72, cachelines: 2 */
/* sum members: 64, holes: 1, sum holes: 4 */
/* padding: 4 */
/* last cacheline: 8 bytes */在這個範例的情況中,壓縮是很容易的,而且它也被這支程式所暗示。輸出顯示在第一個元素後面有個四位元的洞(hole)。這個洞是由結構的對齊需求以及 fill 元素所造成的。很容易發現元素 b –– 其容量為四位元組(由那行結尾的 4 所指出的)–– 完美地與這個間隔(gap)相符。在這個情況下的結果是,間隔不再存在,而這個資料結構塞得進一個快取行中。pahole 工具能自己完成這個最佳化。若是使用 --reorganize 參數,並將結構的名稱加到命令列的結尾,這個工具的輸出即是最佳化的結構、以及使用的快取行。除了移動欄位以填補間隔之外,這個工具也能夠最佳化位元欄位以及合併填充(padding)與洞。更多細節見 [4]。
有個正好大得足以容納尾端元素的洞當然是個理想的情況。為了讓這個最佳化有用,物件本身也必須對齊快取行。我們馬上就會開始處理這點。
pahole 輸出也能夠輕易看出元素是否必須被重新排列,以令那些一起用到的元素也會被儲存在一起。使用 pahole 工具,很容易就能夠確定哪些元素要在同個快取行,而不是必須在重新排列元素時才能達成。這並不是一個自動的過程,但這個工具能幫助很多。
各個結構元素的位置、以及它們被使用的方式也很重要。如同我們已經在 3.5.2 節看到的,晚到快取行的關鍵字組的程式效能是很糟的。這表示一位程式開發者應該總是遵循下列二條原則:
- 總是將最可能為關鍵字組的結構元素移到結構的開頭。
- 存取資料結構、以及存取順序不受情況所約束時,以它們定義在結構中的順序來存取。
以小結構而言,這表示元素應該以它們可能被存取的順序排列。這必須以靈活的方式處理,以允許其它像是補洞之類的最佳化也能被使用。對於較大的資料結構,每個快取行容量的區塊應該遵循這些原則來排列。
不過,若是物件自身不若預期地對齊,就不值得花時間來重新排列它。一個物件的對齊,是由資料型別的對齊需求所決定的。每個基礎型別有它自己的對齊需求。對於結構型別,它的任意元素中最大的對齊需求決定這個結構的對齊。這幾乎總是小於快取行容量。這表示即使一個結構的成員被排列成塞得進同一個快取行,一個被分配的物件也可能不具有相符於快取行容量的對齊。有二種方法能確保物件擁有在設計結構佈局時使用的對齊:
物件能夠以明確的對齊需求分配。對於動態分配(dynamic allocation),呼叫
malloc僅會以相符於最嚴格的標準型別(通常是long double)的對齊來分配物件。不過,使用posix_memalign請求較高的對齊也是可能的。#include <stdlib.h> int posix_memalign(void **memptr, size_t align, size_t size);這個函式將一個指到新分配的記憶體的指標儲存到由
memptr指到的指標變數中。記憶體區塊容量為size位元組,並在align位元組邊界上對齊。對於由編譯器分配的物件(在
.data、.bss等,以及在堆疊中),能夠使用一個變數屬性(attribute):struct strtype variable __attribute((aligned(64)));在這個情況下,不管
strtype結構的對齊需求為何,variable都會在 64 位元組邊界上對齊。這對全域變數與自動變數也行得通。對於陣列,這個方法並不如你可能預期的那般運作。只有陣列的第一個元素會被對齊,除非每個元素的容量是對齊值的倍數。這也代表每個單一變數都必須被適當地標註。
posix_memalign的使用也不是完全不受控制的,因為對齊需求通常會導致碎片與/或更高的記憶體消耗。一個使用者定義型別的對齊需求能夠使用一個型別屬性來改變:
struct strtype { ...members... } __attribute((aligned(64)));這會使編譯器以合適的對齊來分配所有的物件,包含陣列。不過,程式開發者必須留意針對動態分配物件的合適對齊的請求。這裡必須再一次使用
posix_memalign。使用 gcc 提供的alignof運算子(operator)、並將這個值作為第二個參數傳遞給posix_memalign是很簡單的。
之前在這一節提及的多媒體擴充幾乎總是需要對齊記憶體存取。即,對於 16 位元組的記憶體存取而言,位址是被假定以 16 位元組對齊的。x86 與 x86-64 處理器擁有能夠處理非對齊存取的記憶體操作的特殊變體,但這些操作比較慢。對於所有記憶體存取都需要完全對齊的大多 RISC 架構而言,這種嚴格的對齊需求並不新奇。即使一個架構支援非對齊的存取,這有時也比使用合適的對齊還慢,尤其是在不對齊導致一次載入或儲存使用二個快取行、而非一個的情況下。
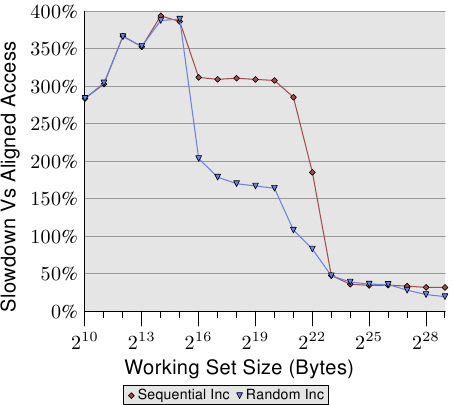
圖 6.4 顯示非對齊記憶體存取的影響。現已熟悉的測試會在(循序或隨機)走訪記憶體被量測的期間遞增一個資料元素,一次使用對齊的串列元素、一次使用刻意不對齊的元素。圖表顯示程式因非對齊存取而招致的效能衰減。循序存取情況下的影響比起隨機的情況更為顯著,因為在後者的情況下,非對齊存取會部分地被一般來說較高的記憶體存取成本所隱藏。在循序的情況下,對於塞得進 L2 快取的工作集容量來說,效能衰減大約是 300%。這能夠由 L1 快取的有效性降低來解釋。某些遞增操作現在會碰到二個快取行,而且現在在一個串列元素上操作經常需要二次快取行的讀取。L1 與 L2 之間的連接簡直太壅塞。
對於非常大的工作集容量,非對齊存取的影響仍然是 20% 至 30% –– 考慮到對於這種容量的對齊存取時間很長,這是非常多的。這張圖表應該顯示對齊是必須被嚴加對待的。即使架構支援非對齊存取,也絕對不要認為「它們跟對齊存取一樣好」。
不過,有一些來自這些對齊需求的附帶結果。若是一個自動變數擁有一個對齊需求,編譯器必須確保它在所有情況下都能夠被滿足。這並不容易,因為編譯器無法控制呼叫點(call site)與它們處理堆疊的方式。這個問題能夠以二種方式處理:
- 產生的程式主動地對齊堆疊,必要時插入間隔。這需要程式檢查對齊、建立對齊、並在之後還原對齊。
- 要求所有的呼叫端都將堆疊對齊。
所有常用的應用程式二進位介面(application binary interface,ABI)都遵循第二條路。如果一個呼叫端違反規則、並且對齊為被呼叫端所需,程式很可能會失去作用。不過,對齊的完美保持並不會平白得來。
在一個函式中使用的一個堆疊框(frame)的容量不必是對齊的倍數。這表示,若是從這個堆疊框呼叫其它函式,填充就是必要的。很大的不同是,在大部分情況下,堆疊框的容量對編譯器而言是已知的,因此它知道如何調整堆疊指標,以確保任何從這個堆疊框呼叫的函式的對齊。事實上,大多編譯器會直接將堆疊框的容量調高,並以它來完成操作。
如果使用可變長度陣列(variable length array,VLA)或 alloca,這種簡單的對齊處理方式就不合適。在這種情況下,堆疊框的總容量只會在執行期得知。在這種情況下可能會需要主動的對齊控制,使得產生的程式碼(略微地)變慢。
在某些架構上,只有多媒體擴充需要嚴格的對齊;在那些架構上的堆疊總是當作普通的資料型別進行最低限度的對齊,對於 32 與 64 位元架構通常分別是 4 或 8 位元組。在這些系統上,強制對齊會招致不必要的成本。這表示,在這種情況下,我們可能會想要擺脫嚴格的對齊需求,如果我們知道不會依賴它的話。不進行多媒體操作的尾端函式(tail function)(那些不呼叫其它函式的函式)不必對齊。只呼叫不需對齊的函式的函式也不用。若是能夠識別出夠大一組函式,一支程式可能會想要放寬對齊需求。對於 x86 的二元檔,gcc 擁有寬鬆堆疊對齊需求的支援:
-mpreferred-stack-boundary=2
若是這個選項(option)的值為 ,堆疊對齊需求將會被設為 位元組。所以,若是使用 2 為值,堆疊對齊需求就被從預設值(為 16 位元組)降低成只有 4 位元組。在大多情況下,這表示不需額外的對齊操作,因為普通的堆疊推入(push)與彈出(pop)操作無論如何都是在四位元組邊界上操作的。這個機器特定的選項能夠幫忙減少程式容量,也能夠提升執行速度。但它無法被套用到許多其它的架構上。即使對於 x86-64,一般來說也不適用,因為 x86-64 ABI 要求在 SSE 暫存器中傳遞浮點數參數,而 SSE 指令需要完整的 16 位元組對齊。然而,只要能夠使用這個選項,就能造成明顯的差別。
結構元素的高效擺放與對齊並非資料結構影響快取效率的唯一面向。若是使用一個結構的陣列,整個結構的定義都會影響效能。回想一下圖 3.11 的結果:在這個情況中,我們增加陣列元素中未使用的資料總量。結果是預取越來越沒效果,而程式 –– 對於大資料集 –– 變得越來越沒效率。
對於大工作集,盡可能地使用可用的快取是很重要的。為了達到如此,可能有必要重新排列資料結構。雖然對程式開發者而言,將所有概念上屬於一塊兒的資料擺在同個資料結構是比較簡單的,但這可能不是最大化效能的最好方法。假設我們有個如下的資料結構:
struct order {
double price;
bool paid;
const char *buyer[5];
long buyer_id;
};
進一步假設這些紀錄會被存在一個大陣列中,並且有個經常執行的工作(job)會加總所有帳單的預期付款。在這種情境中,buyer 與 buyer_id 使用的記憶體是不必被載入到快取中的。根據圖 3.11 的資料來判斷,程式將會表現得比它能達到的還糟了高達五倍。
將 order 切成二塊,前二個欄位儲存在一個結構中,而另一個欄位儲存在別處要好得多。這個改變無疑提高程式的複雜度,但效能提升證明這個成本的正當性。
最後,讓我們考慮一下另一個 –– 雖然也會被應用在其它快取上 –– 主要是影響 L1d 存取的快取使用的最佳化。如同在圖 3.8 看到的,增加的快取關聯度有利於一般的操作。快取越大,關聯度通常也越高。L1d 快取太大,以致於無法為全關聯式,但又沒有足夠大到要擁有跟 L2 快取一樣的關聯度。若是工作集中的許多物件屬於相同的快取集,這可能會是個問題。如果這導致由於過於使用一組集合而造成逐出,即使大多快取都沒被用到,程式還是可能會受到延遲。這些快取錯失有時被稱為衝突性錯失(conflict miss)。由於 L1d 定址使用虛擬位址,這實際上是能夠受程式開發者控制的。如果一起被用到的變數也儲存在一塊兒,它們屬於相同集合的可能性是被最小化的。圖 6.5 顯示多快就會碰上這個問題。
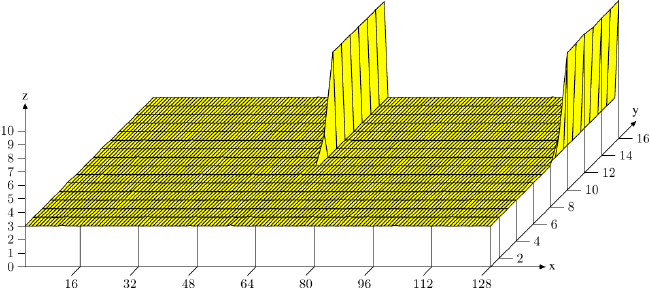
在這張圖中,現在熟悉的、使用 NPAD=15 的 Follow30 測試是以特殊的配置來量測的。X 軸是二個串列元素之間的距離,以空串列元素為單位量測。換句話說,距離為 2 代表下一個元素的位址是在前一個元素的 128 位元組之後。所有元素都以相同的距離在虛擬記憶體空間中擺放。Y 軸顯示串列的總長度。僅會使用 1 至 16 個元素,代表工作集總容量為 64 至 1024 位元組。Z 軸顯示尋訪每個串列元素所需的平均週期數。
圖中顯示的結果應該不讓人吃驚。若是被用到的元素很少,所有的資料都塞得進 L1d,而每個串列元素的存取時間僅有 3 個週期。對於幾乎所有串列元素的安排都是如此:虛擬位址以幾乎沒有衝突的方式,被良好地映射到 L1d 的槽(slot)中。(在這張圖中)有二個情況不同的特殊距離值。若是距離為 4096 位元組(即,64 個元素的距離)的倍數、並且串列的長度大於八,每個串列元素的平均週期數便大幅地增加。在這些情況下,所有項目都在相同的集合中,並且 –– 一旦串列長度大於關聯度 –– 項目會從 L1d 被沖出,而下一輪必須從 L2 重新讀取。這造成每個串列元素大約 10 個週期的成本。
使用這張圖,我們能夠確定使用的處理器擁有一個關聯度 8、且總容量為 32kB 的 L1d 快取。這表示,這個測試能夠 –– 必要的話 –– 用以確定這些值。可以為 L2 快取量測相同的影響,但在這裡更為複雜,因為 L2 快取是使用實體位址來索引的,而且它要大得多。
但願程式開發者將這個數據視為值得關注集合關聯度的一種暗示。將資料擺放在二的冪的邊界上足夠常見於現實世界中,但這正好是容易導致上述影響與效能下降的情況。非對齊存取可能會提高衝突性錯失的可能性,因為每次存取都可能需要額外的快取行。

如果執行這種最佳化,另一個相關的最佳化也是可能的。AMD 的處理器 –– 至少 –– 將 L1d 實作為多個獨立的 bank。只有當二個資料字組儲存在不同的 bank 中或儲存在同一索引(index)下相同的 bank 中,L1d 快取才能在每一個週期裡拿到二個字組。bank 位址是以虛擬位址的低位元編碼的,如圖 6.6 所示。假若會共同使用的變數也儲存在一起,則它們也會有高可能性在不同的 bank 中或在同一索引下相同的 bank 中。
28. 我們這裡忽略可能會改變上溢位(overflow)、下溢位(underflow)、或是四捨五入(rounding)的發生的算術影響。 ↩
譯註. 原文說法較簡略,作者的意思是:在一開始三層迴圈的實作中,最內部的每一次k迴圈迭代同時處理res[i][j] += mul1[i][k] * mul2[k][j]與res[i][j + 1] += mul1[i][k] * mul2[k][j + 1]。由於才剛存取過mul2[k][j]與res[i][j],所以mul2[k][j + 1]與res[i][j + 1]還在 L1d 快取中,因而降低錯失率。後述的方法是這個方法的一般化(generalization)。 ↩
29. 理論上在 1999 年修訂版引入 C 語言的 restrict 關鍵字應該解決這個問題。不過編譯器還是不理解。原因主要是存在著太多不正確的程式碼,其會誤導編譯器、並導致它產生不正確的目的碼(object code)。 ↩
30. 測試是在一台 32 位元機器上執行的,因此 NPAD=15 代表每個串列元素一個 64 位元組快取行。 ↩