7.1 記憶體操作分析
進行記憶體操作分析需要與硬體的進行整合。當然也可只透過軟體收集某些資訊,但這些資訊往往過於粗糙或屬於模擬而非真實量測。第 7.2 和 7.5 節裡我們會展示一些模擬的例子。在此章節,我們會專注在可量測的記憶體所帶來的功效。
在 Linux 作業系統可透過 Oprofile 來監控效能。如參考書目2所寫,Oprofile 提供不間斷的效能分析與友善的界面來提供量測功能並以統計數據方式呈現。Oprofile 並非效能測量的唯一的方式,許多 Linux 開發者也正在開發 pfmon 來適用於某些特殊情境。
Oprofile 提供簡單的界面,即便選擇 GUI 仍可運行於裝置底層。使用者必須在處理器間發生的事件 (event) 中選擇。儘管處理器的架構說明書記載了這些事件的細節,但若需對資料進行分析往往需要對處理器本身有深入了解。另一個問題是對收集的數據進行解釋時。由於量測結果為絕對值且可任意增長。對於某個已知的計數器來說,數字要多高才算太高呢?
針對這個問題首先避免觀測單一計數器的絕對值,可將多個計數器的數值一同納入參考。處理器一次可監控不只一個事件;再來可計算所有收集數據的比值。可能可獲得更好比較的結果。計算時通常以處理時間 (process time) 作除數,例如時脈週期數 (clock cycles) 或指令數。以程式性能的初步測試而言,這二個數字具有參考的價值。
圖 7.1 為對一個簡單隨機「跟隨」測試資料進行量測的結果,縱軸為 CPI(Cycles Per Instruction)數值,橫軸則為工作集 (working set) 容量。在大多數 Intel 處理器上紀錄這個事件的變數名稱為 CPU_CLK_UNHALTED 和 INST_RETIRED 。從縮寫大概可猜到,前者計算 cpu 的時脈週期,後者則計算指令數。我們看到類似於每個元素的週期量測的圖片。對小工作集 (working set) ,比值為 1.0 有時甚至更低。這些計算結果皆在 Intel Core 2 處理器上進行,此處理器具有多純量 (multi-scalar) 特性,可同時處理多個指令。對於不受記憶體頻寬限制的程式,比率可顯著低於 1.0 ,但以此案例來說,1.0 的結果已經非常好了。
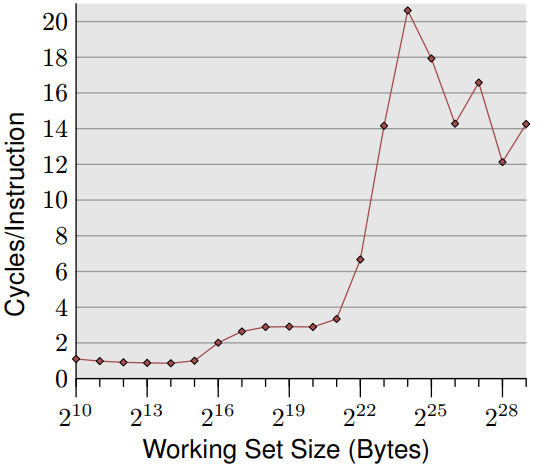
當 L1d 快取無法儲存所有計算數值時,CPI 會跳升到接近但低於 3.0 。需要注意 CPI 比率是將所有指令對 L2 的存取成本再取平均,而非只計算牽涉記憶體存取的指令。透過列表上的資料的週期,可計算出每個列表上項目所需的指令數量。即使 L2 快取不足時,CPI 比率會跳躍至超過 20。但這些都是可預期的結果。
但效能測量計數器應該要讓我們能更深入地了解處理器內部運作。因此我們需要思考處理器的實作細節。在這個章節我們非常在乎快取處理的細節,因此必須查看與快取相關的事件。但這些事件以及相關名稱與計數方式都與處理器息息相關。這就是為什麼 oprofile 有其不便,就算使用介面非常友善:程式開發者仍必須事先了解計數器相關詳細資料。在附錄 B 中會展示一些處理器的詳細資訊。
對於 Intel Core 2 處理器,所對應的事件分別為 L1D_REPL 、DTLB_MISSES 和 L2_LINES_IN。後者可測量所有未命中以及由指令所造成的未命中,而非硬體預取 (prefetch) 所造成 。隨機「跟隨」測試的結果如圖 7.2 所示。
所有比值結果都是使用除役 (retired) 指令(INST_RETIRED)的數量計算。因此要計算快取未命中率,還必須從 INST_RETIRED 中減去所有讀取資料和儲存資料的指令,使得記憶體操作的實際快取未命中率比圖中顯示的數字更高。
其中 L1d 的快取未命中占大多數,對 Intel 處理器而言由於使用包含快取(inclusive caches),代表可能會出現 L1d 快取未命中的情況。該處理器具有 32k 容量的 L1d 快取,因此可看到,如同預期,L1d 未命中率從零開始上升到將近工作集的容量(除了列表資料集外,還可能有其他原因觸發快取,因此增加集中在 16k 和 32k 之間 。硬體預取可將 L1d 快取未命中率保持在約 1%,直到工作集超過 64k 之後,L1d 未命中率急劇上升。
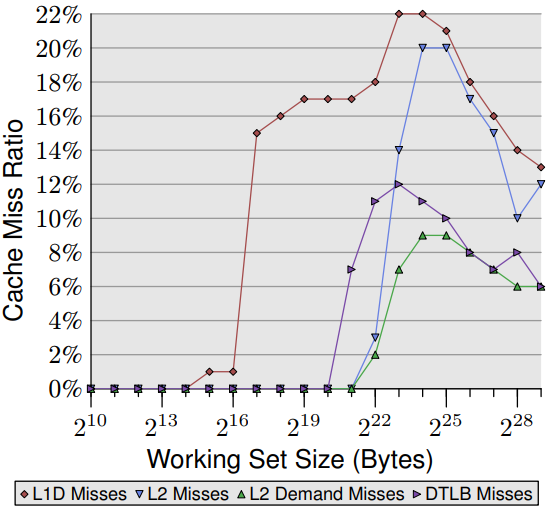
L2 快取未命中率一直保持為零,直到 L2 快取完全用盡為止。其他原因造成的 L2 快取未命中可姑且忽略不計,一旦超過 L2 快取容量(221位元),未命中率就會上升。另一件值得注意的部份為 L2 快取需求未命中率並非為零。表示硬體預取器沒有加載後續指令所需的所有高速快取內容。隨機存取會影響指令預取的效果。可跟圖 7.3 循序非隨機讀取的測試版本一起比較。
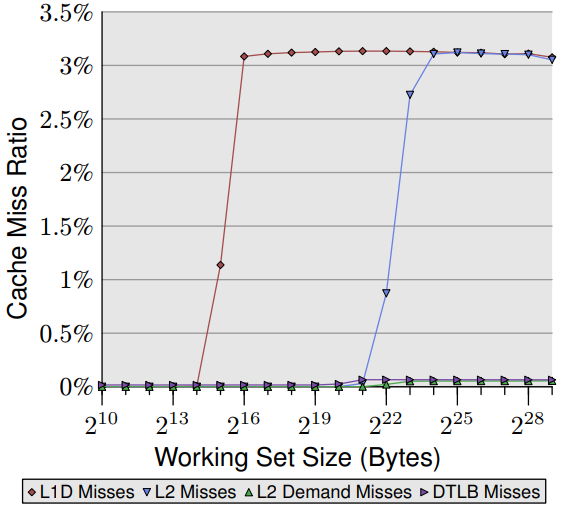
這張圖中可看到 L2 的需求未命中率基本上為零(注意此圖的度量衡與圖 7.2 不同)。對於循序存取硬體預取器運作得非常完美:幾乎所有 L2 快取未命中都由預取器所造成。從 L1d 和 L2 快取未命中率相同來判斷,幾乎所有 L1d 快取未命中都被 L2 快取處理,沒有造成進一步延遲。這樣的情境對所有程式都是最理想卻很難成真。
在這二個圖中,第四條線是 DTLB 未命中率( Intel 有專門為程式碼和資料所設置的 TLB ,DTLB 就是儲存資料用的 TLB )。對隨機存取的情況,DTLB 的未命中率就非常高且會導致延遲。但有趣的地方在 DTLB 的代價早在 L2 快取未命中之前就已確定。對循序存取情況,DTLB 的未命中率基本上為零。
回到 6.2.1 節中的矩陣乘法示例以及 A.1 節中的示例程式碼,我們可利用另外三個計數器。SSE_HIT_PRE 、SSE_PRE_MISS 和 LOAD_PRE_EXEC 來查看軟體預取 (prefetch) 的效果如何。如果執行 A.1 節中的程式碼,我們可得到以下結果:
| 描述 | 比值 |
|---|---|
| 有用的 NTA 預取 | 2.84% |
| 延遲的 NTA 預取 | 2.56% |
NTA(非時間對齊)預取比率表示有多少的預取指令已被執行,因此不需要額外的功夫來處理。這表示處理器必須浪費額外的時間來解譯預取的指令並到快取尋找相關內容。因此軟體的表現很大程度取決於所使用的處理器快取容量;以及硬體預取器的效能。
若是只看 NTA 預取比值不太準確。因為比值表示所有預取指令中有 2.65% 產生延遲無法發揮效益。這些預取指令在執行之前需要將相關的資料從快取中取出。因此從數值來看只有 2.84% + 2.65% = 5.5% 的預取指令有用。以所有有用的 NTA 預取指令來看 48% 沒有及時完成。由此得知程式碼還有改進的空間如下:
- 大多數的預取指令沒有幫助
- 預取指令要依照硬體特性做調整
這個部份可留給讀者去練習如何在硬體上調整出最佳解決方案。硬體規格扮演至關重要的角色,對 Intel Core 2 處理器而言,SSE 運算的延遲為 1 個時脈週期譯註2。若是較舊版本則為 2 個時脈週期,這表示硬體預取器和預取指令有更多的前置時間來讀取數據。
- Oprofile 執行隨機分析。但只記錄某個事件的第 N 次(其中 N 是每個事件最小值的閾值),以避免造成系統的負擔。某些情況可能會觸發 100 次事件,但很有可能不會在報告中顯示。
- 並非所有事件都能被精準的記錄。例如在記錄特定事件時指令計數器(instruction pointer)譯註1的結果往往可能是錯誤。處理器的多純量 (multi-scalar) 特性可使計算結果很難 100% 正確。但在某些處理器上特定事件可精確紀錄。
這些已標記的列表不僅有助於解讀預取資訊,每個事件都以程式計數器來記錄,因此可精準定位程式中的其他熱點。執行頻繁的位置通常會是許多 INST_RETIRED 事件的來源,因此值得進行額外調整。如果觀測結果有許多快取未命中時,則需要透過預取指令來避免快取未命中。
有一種事件可在沒有硬體支援的情況下測量分頁錯誤 (page fault) 。作業系統在解決分頁錯誤時會將結果紀錄。並分成以下二種類型的分頁錯誤:
- 次要分頁錯誤 對於未使用的匿名頁面(未被任何檔案紀錄使用)、寫入時才複製 (copy-on-write) 頁面以及內容已經在記憶體某處的其他頁面。
- 主要分頁錯誤 需要讀取磁碟以獲取檔案支援(或替換頁面出去 (swapped-out) )的資料。
很明顯,主要分頁錯誤比次要分頁錯誤要付出更多的代價。但次要分頁錯誤所造成的損失也不容忽視。在任何情況下分頁錯誤都需要進入作業系統核心來進行操作,無論是尋找新的頁面,清除或寫入需要的資料,都必須修改頁表樹 (page table tree) 。最後還需同步那些讀取或修改頁表樹的其他任務並可能引發更多延遲。
最簡單讀取分頁錯誤的方法是透過 time 工具,而不是 shell 的內建命令。如下圖 7.4 中所示。
$ time ls /etc
[...]
0.00user 0.00system 0:00.02elapsed 17%CPU (0avgtext+0avgdata 0maxresident)k
0inputs+0outputs (1major+335minor)pagefaults 0swaps
圖 7.4:time 工具的相關內容
注意圖中最後一行。time 指出 1 個主要分頁錯誤的和 335 個次要的分頁錯誤。確切數字可能不同;特別是如果立刻重複運行可能會顯示現在完全沒有主要的分頁錯誤。如果程式執行相同操作,在系統環境沒有任何變化情況下,總分頁錯誤的數字將保持穩定。
對分頁錯誤影響最大階段在程式啟動階段。使用每個頁面都會產生分頁錯誤;特別是 GUI 應用程式,使用的頁面越多,程式運作所需的時間與準備時間就越長。在 7.5 節中,我們會介紹一個專門用於測量初始化時間的工具。
time 透過 rusage 來運作。wait4 系統呼叫在親代行程等待子行程終止時會寫入 strcut rusage ; 正好符合 time 的需求。但行程仍可獲取自身資源使用資訊(正是 rusage 命名由來)或已終止子行程的資源使用資訊。
#include <sys/resource.h>
int getrusage(__rusage_who_t who, struct rusage *usage)
getrusage透過參數 who 明確表示哪個行程要求資訊。目前只有 RUSAGE_SELF 和
RUSAGE_CHILDREN 二個變數有定義。資源使用狀況計算到當每個子行程截至終止的加總,而非個別使用情況。為了能夠允許存取特定執行緒的資料,未來可能會新增 RUSAGE_THREAD 來處理單一個別執行緒計算。rusage 結構定義了包括執行時間、發送和使用行程間通訊(IPC)數量及分頁錯誤數在內的各項計算值。分頁錯誤資訊可在 ru_minflt 和ru_majflt 中獲得。
對於想透過減少分頁錯誤來增加程式效能的程式開發者可查看這些資訊,收集分析並做出比較。以系統面而言,如果使用者擁有足夠系統權限,也可透過 /proc/<PID>/stat 看到相關資訊。其中 <PID> 是欲查看的行程 ID ,分頁錯誤的數值則位在第 10 到第 14 欄。分別是行程及其子程的累進次要和主要分頁錯誤數。
譯註1. 在 x86 家族的微處理器,稱為 instruction pointer,或簡稱 IP,詳細可見 Program counter。 ↩
譯註2. x86 家族微處理器的指令延遲可見: https://www.agner.org/optimize/instruction_tables.pdf。 ↩